Evolution Manuscript Edits
Received the reviews of our evolution manuscript back with relatively straight-forward edits. (Yay!)
Need better citations of the early history in phylogenetic comparative methods, which is quite rich. Reviewer pointed me to an early book chapter by AW Edwards and LL Cavalli-Sforza introducing Brownian motion model in 1964, of which Joe Felsenstein has a nice description (of this and other work) in his 1988 review(Felsenstein, 1988).
See private review notes for details.
Early bursts
Hadn’t added a wrapper to the early burst model of geiger in pmc. There’s a great paper by Harmon et al. (Harmon et. al. 2010) last year looking at 49 different phylogenetic trees and comparing BM, OU, and EB on body size, 39 on body shape measurements, and also consider all subclades of n>10 species, finding surprisingly little evidence for EB model. I’d suspect many of these examples fall into the class “cannot tell” rather than definitively belonging to one or the other model. (See supplementary figure 1).
The authors use AICc, and include a bootstrap analysis which suggests relatively robust model choice above 10 taxa. The reason for this is that the models being compared are not estimated from the data. The authors fix parameters for each of the three models, BM, OU, EB, and simulate 100 trait data sets (on each tree). On each, one tends to make the correct choice by AICc.
In our approach, we estimate BM/OU/EB model parameters from the data, and simulate all replicates under that. Imagine a rich data set that is clearly from EB by any criteria. The estimated BM model for this data-set has a worse log-likelihood. Yet simulations from that estimated model can be very difficult to tell apart from the simulations of the EB model that has been estimated from the same data.
Consequently we find in our approach that we cannot tell between data simulated under the specified EB model and the other models:
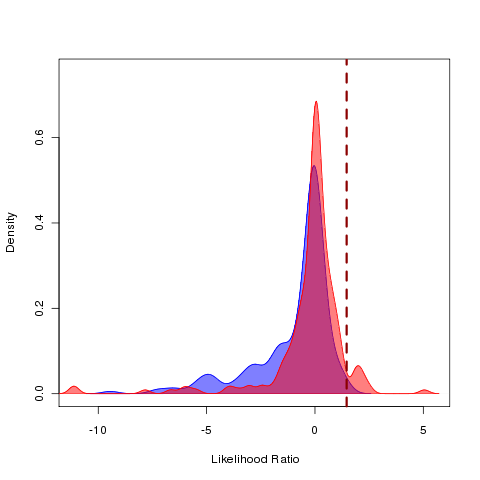
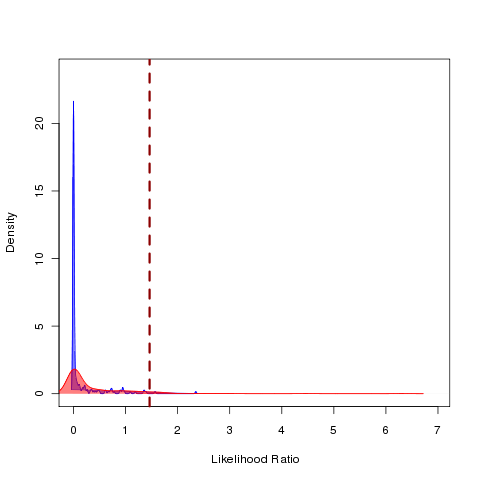
AICc
Also added AICc comparison along with AIC and BIC (calculated but the updated plot command). Of course as none of the criteria estimate any measure of uncertainty, it doesn’t do any better, just pushes the false positive and false negative errors around a bit:
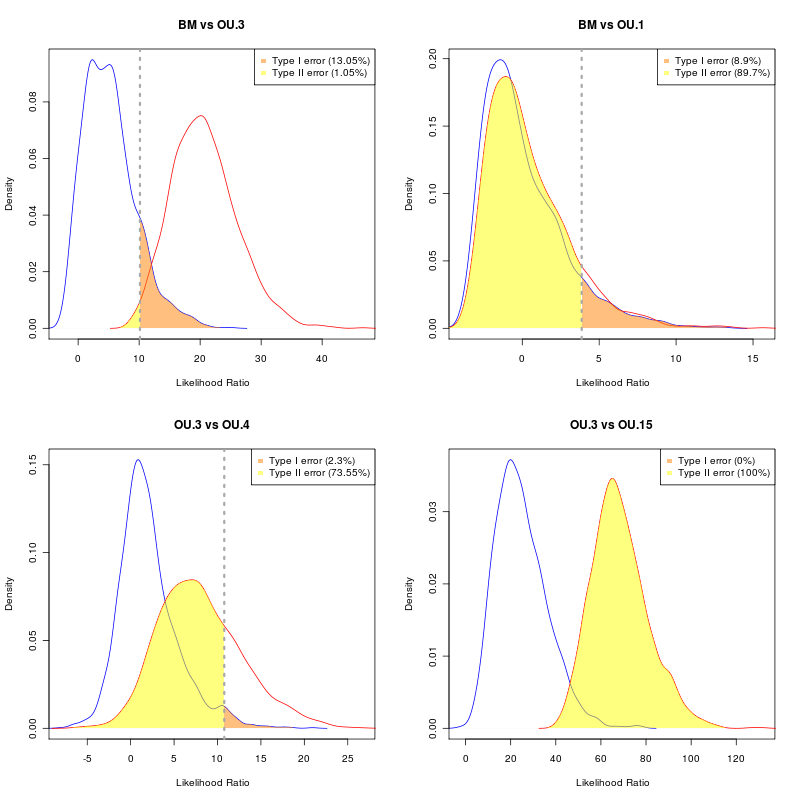

However, summary patterns are still going to be necessary, particularly for large meta-analyses such as the EB example. AUC of the ROC might be a promising thing to explore here.
wrightscape
Luke Mahler is trying out my wrightscape code (prerelease version, from github). Some trouble apparently in compiling from source, probably in getting RTools and GSL libraries to cooperate, luckily winbuilder builds me a quick binary successfully, now available on github downloads.
Doesn’t really have any good demos set up yet. Should add some use cases. Might be interesting to test the sets studied by Eastman et al.(Eastman et. al. 2011), Turtles (see Jaffe et al. 2011(Jaffe et. al. 2011); 226 species) and female body mass for primates (see Redding et al. 2010(REDDING et. al. 2010); complete sampling of 233 species).
Compute Jobs
early_burst_example.R added and submitted to farm.
rerunning power_analysis.R for comparison on zero.
Misc
Wordpress academic plugins list from Peter Krautzberger Adam Wilson’s page at UConn
References
Felsenstein J (1988). “Phylogenies And Quantitative Characters.” Annual Review of Ecology And Systematics, 19. ISSN 0066-4162, https://dx.doi.org/10.1146/annurev.es.19.110188.002305.
Harmon L, Losos J, Jonathan Davies T, Gillespie R, Gittleman J, Bryan Jennings W, Kozak K, McPeek M, Moreno-Roark F, Near T, Purvis A, Ricklefs R, Schluter D, Schulte II J, Seehausen O, Sidlauskas B, Torres-Carvajal O, Weir J and Mooers A (2010). “Early Bursts of Body Size And Shape Evolution Are Rare in Comparative Data.” Evolution. https://dx.doi.org/10.1111/j.1558-5646.2010.01025.x.
Eastman J, Alfaro M, Joyce P, Hipp A and Harmon L (2011). “A Novel Comparative Method For Identifying Shifts in The Rate of Character Evolution on Trees.” Evolution, 65. https://dx.doi.org/10.1111/j.1558-5646.2011.01401.x.
Jaffe A, Slater G and Alfaro M (2011). “The Evolution of Island Gigantism And Body Size Variation in Tortoises And Turtles.” Biology Letters, 7. ISSN 1744-9561, https://dx.doi.org/10.1098/rsbl.2010.1084.
REDDING D, DeWOLFF C and MOOERS A (2010). “Evolutionary Distinctiveness, Threat Status, And Ecological Oddity in Primates.” Conservation Biology, 24. https://dx.doi.org/10.1111/j.1523-1739.2010.01532.x.