I thought I had already fixed this problem. I thought I already had a way to recover the code and parameter values of figures saved in my image log. Grab the SHA hash from the comment, go to the relevant repository on github, search the commit history for the commit, find the version of that file that was current at that time of commit (which could be in an earlier version if nothing had changed…) and so forth… Instead, I would catch myself re-running the code with parameters I knew (I’d scribble somewhere), just so I could be sure. And these are not fast codes to re-run. Sure, it was possible. It just wasn’t easy enough. So I took a few hours to rewrite my socialR package to handle this properly. Goodbye SHA hash and search, hello direct links.
Linked reproducible scripts
I run a script and it produces some graphical output, like this:
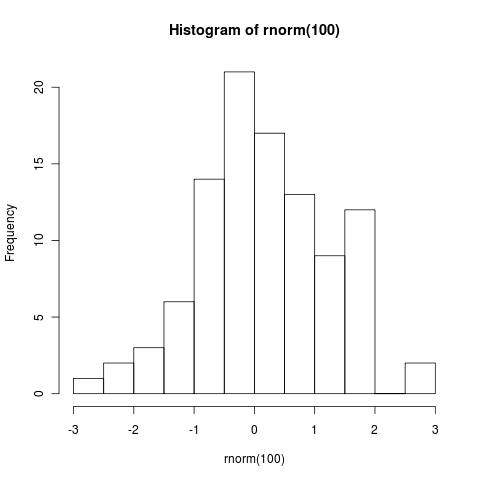
Clicking on the image takes you to its place in the flickr photostream. It has been automatically tagged, and the comment includes a direct link to a version-stable copy of the sourcecode that created it. From the code page, we get a lot more information than just the source.
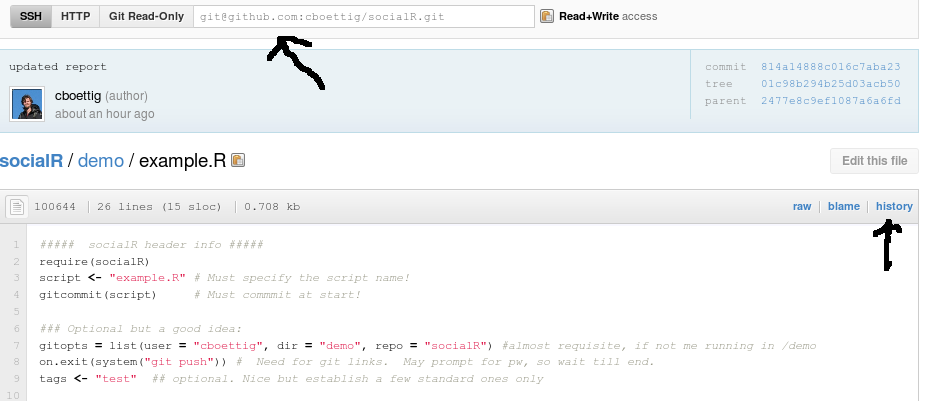
We can see the package that it depends on, and grab all the dependencies by using git to pull this SHA commit hash.
We can view the commit history of this particular file (click history). Clicking then on any item shows a marked up diff of the file.
If logged in to github, I can add line notes and comments to the diff pages, just as I can add comments in flickr.
Full suite of other abilities of both flickr and github, comments. For instance, I can actually edit and commit changes to the code directly on github, or use flickr’s built-in photo editor. Tag, search, and social functions also available.
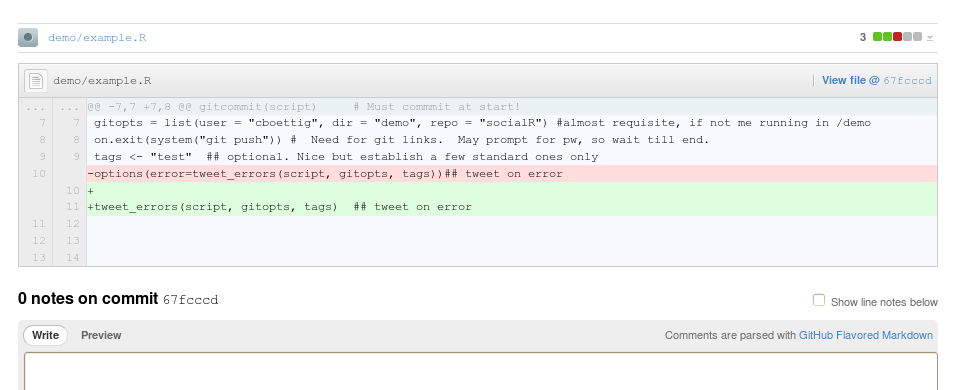
The links to the images and code can also be sent to me from my computer’s twitter account:
[blackbirdpie url=“https://twitter.com/#!/tweeting_cpu/status/79278116543012864”]
Viewing the tweet in the browser will actually show the image with the tweet, otherwise the links can quickly show me the figures or code. A similar tweet can be sent on the case of an error (if in batch mode only, the machine knows not to tweet if I’m right here), giving a timestamped link to the code and the name of the machine on which the run occurred. A mention can get my attention and a unique hash tags help quickly check for other output by the same machine.
https://twitter.com/#!/tweeting_cpu/status/79278121827827713
Adding Reporting to the R Scripts
A bit more overhead is required in the code than simply loading the package and calling the report function (currently called “upload”).
We need to specify the script name.
We also must specify the commits manually, (not necessary if everything is committed before each batch run … but I’m not that perfect).
We must define a bit of information about the repository structure, though it will guess for my standard use cases.
Then we can add optional information like tags, turn on the error reporting, etc. An example script with these features looks like:
[gist id=1019567]
Possible concerns
Commits only the current script. This assures the version number corresponds to a commit to this actual file, though links will work correctly regardless. (Do all files exist as url at the end of all commits? – Yes.)
Possible errors: installed version is older than the other files committed. Would ideally run R CMD INSTALL and git commit -a before running any scripts, but oh well.