Alan Meeting, 10a
Good meeting discussing warning signals manuscript details and organization. Particularly on the best way to present some of the major conceptual and semantic elements: there are many ways to describe the same thing, each of which carries a lot of semantic baggage.
Do we choose to present this as:
As Hypothesis Testing
Null = isn’t a loss of stability (distribution produced by the MLE model of no stability loss), hypothesis = there is (distribution produced by, MLE model with stability loss) determine p value for falsely rejecting the null and the power of the statistical test.
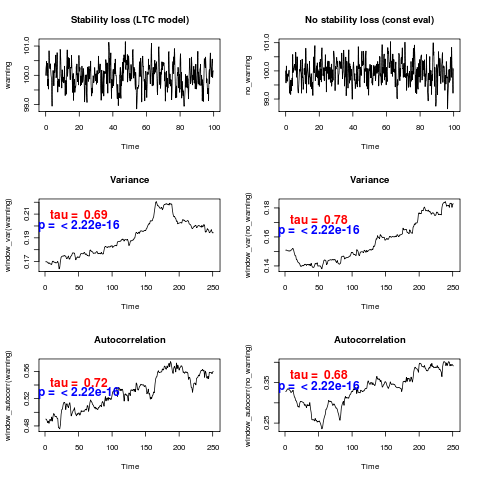
Advantages: familiar framework, though heavily misunderstood. For instance, the existing warning signals literature uses correlation tests on the windowed averages of the warning signal statistics. Only the
Problems with this approach: Seen as old-school. Often misunderstood. Used incorrectly in the current approaches – they test a null that points are uncorrelated, having generated each of those points from overlapping windows in the same data set (which is also a time series!) Somehow those using information-criteria based model choice imagine they are working in a different statistical paradigm by not attempting to quantify error.
As Model Choice
Comparison of nested models – stability loss has an extra parameter for the rate of decay.
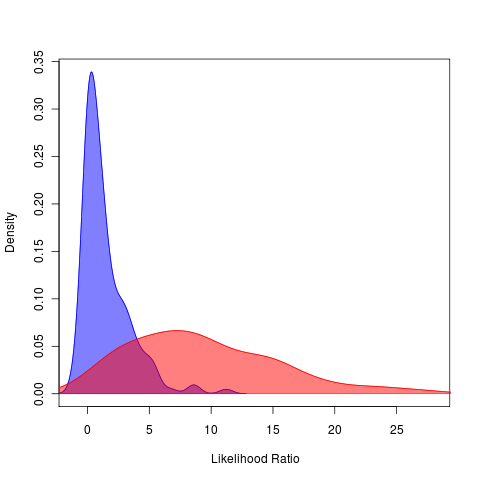
Can be expressed as information criteria or likelihood ratio tests, (distribution of LR isn’t chi-squared since loss of stability model is restricted to only decreasing values, so null model is at the limit of parameter range). IC don’t quantify the probability of error we are trying to illustrate.
Might compare Bayesian framework: we would compare posterior odds, or reversible jump across models.
So, some discussion of whether it was going to be necessary to mention information criteria performance at all, and if so, where (intro/body vs methods/supplement?) Alan suggests emphasizing. More to juggle in the intro
Model Adequacy / Goodness of Fit
Perhaps “Model Adequacy” is the best way to describe this, if only because it is already used(Sullivan & Joyce, 2005) in describing parametric bootstrap approach. References Goldman (1993)Goldman, 1993 in which this is done following Cox 1961/62, but as a model adequacy test in the following way:
The focal model (whose “adequacy” we wish to test) is treated as the null, and the arbitrarily general model is treated as the test model (ironically it is the test model, not the null model, which is being used as the benchmark). Goldman specifies the most unconstrained model for the phylogenetic inference from alignment data that still has i.i.d. sites. Then adequacy is assessed then by whether or not the observed ratio falls in the tails of the distribution.
This test of adequacy does not seem the sense in which Cox (1962) originally proposed the method, which was more along the lines of our general model test. Other work(McLachlan, 1987) has also applied the approach in the model selection sense that we use it, rather than Goldman’s test of adequacy.
Note that none of the proposed methods simulate under the test distribution.
As Data Adequacy
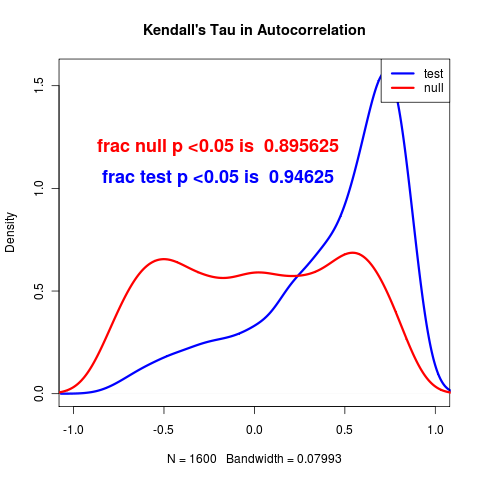
Because we simulate under both models, we have the unique ability to emphasize how likely we are to be able to distinguish between the models being compared.
Each of the statistical paradigms described above set model choice decisions (the null model should only be rejected at certain probability, the better model should trade off complexity of added parameters, etc). It is the role of management to trade off between the risk of false alarm and the risk of undetected events. Our approach provides the relative rates of each kind of error given the data and leaves this choice to the decision-maker. Further, it provides a clear illustration of how these error rates depend on the amount of data available – another key facet absent from the standard emphasis. For this reason it’s tempting to emphasize this as a different framework, though any might be used (despite the fact that many of the above are used incorrectly).
Manuscript Notes
Considering best way to phrase the warning signals approach
Present as a Simulation-study style study vs methodological style (non-parametric bootstrapping)?
Focus on difference between summary statistic vs a full likelihood approach, or focus on estimating error rates and having sufficient information to tell (regardless of the statistic)?
Current paper uses the former of both, following the outline
(detection has risks & limits)
(exist != detection)
(Explains detection problem)
(Simple = General: Introducing the theory)
(summary statistics no substitute for the full data)
References
Sullivan J and Joyce P (2005). “Model Selection in Phylogenetics.” Annual Review of Ecology, Evolution, And Systematics, 36. ISSN 1543-592X, https://dx.doi.org/10.1146/annurev.ecolsys.36.102003.152633.
McLachlan G (1987). “on Bootstrapping The Likelihood Ratio Test Stastistic For The Number of Components in A Normal Mixture.” Applied Statistics, 36. ISSN 00359254, https://dx.doi.org/10.2307/2347790.
Statistical Tests of Models of Dna Substitution, Nick Goldman, (1993) Journal of Molecular Evolution, 36 10.1007/BF00166252